
Monday, July 04, 2022
How to get PDF data extraction right for your digital transformation journey?
By
Subhransu Majhi, Anirudh Singh
How to get PDF data extraction right for your digital transformation journey?
"Data, data everywhere but only a drop of it analyzed"
This is not an attempt at creating a catchy quote; it's a fact. According to reports, 80% to 90% of data within organizations is unstructured
and most of it is locked in documents and images.
Analysts suggest that only 0.5% of data is analyzed. Moreover, 70% of organizations still have paper-based process dependencies.
Suppose your business analyst comes to you with this month's data trends. You have to decide which areas of your organization you want to improve or change.
But how much can you get out of this process when you are sitting on a goldmine of data lying untapped in images, PDF files, printouts, and emails?
Out of all the forms mentioned, the Portable Document Format (PDF) is the go-to file format for sharing and exchanging business data. Why is it so popular among enterprises?
Because PDF keeps the content in its original form, its format is universal, it's small in size, it can be password protected and it works on every operating system.
Globally, 2.5 quintillion bytes of digital data are generated in a single day, and digitization of that data is the first step toward Digital Transformation.
According to reports by Allied Market Research, digital transformation generated USD 52.44 billion in 2019 for the BFSI industry. COVID-19 has only pushed enterprises to figure out quicker ways to get on the Digital Transformation train.
This means enterprises, as part of their first step, have to work on data extraction from not only the non-digital medium but digital medium as well.
Now there was a time when PDF data extraction was a time-consuming process. But with RPA, Machine Learning, and AI technology, we are in an era of automated data extraction whereas a large pool of employees used to read, infer, and extract information from documents.
If you look for such solutions online, you will come across the following options:
- Ready-to-use extraction websites which provide you with very basic PDF extraction like extract pdf, smallpdf, ilovepdf, etc.
- The commercial PDF extraction software like PDFelement, PDFtables, Adobe Acrobat, etc.
- AI-enabled PDF extraction solutions that cloud companies like AWS, Azure, etc. provide
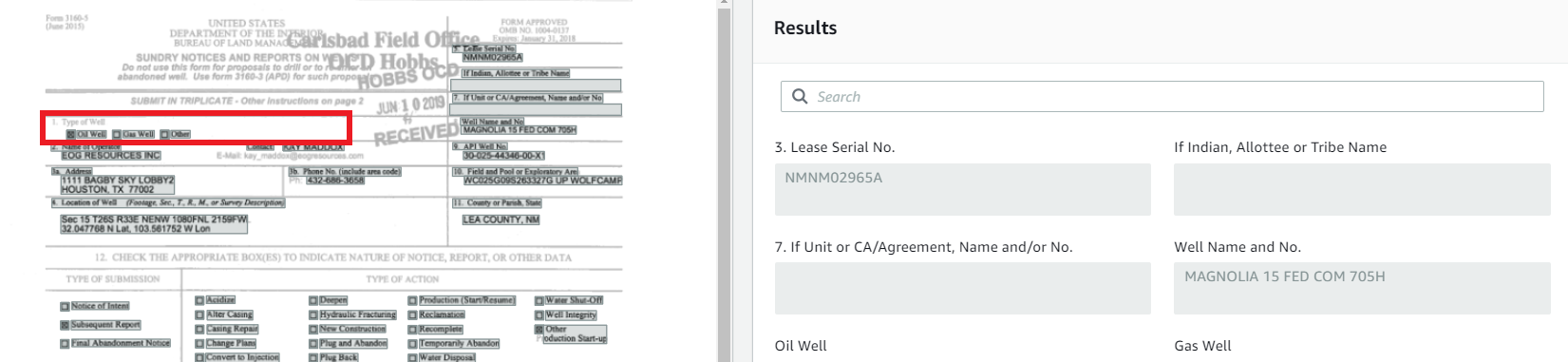
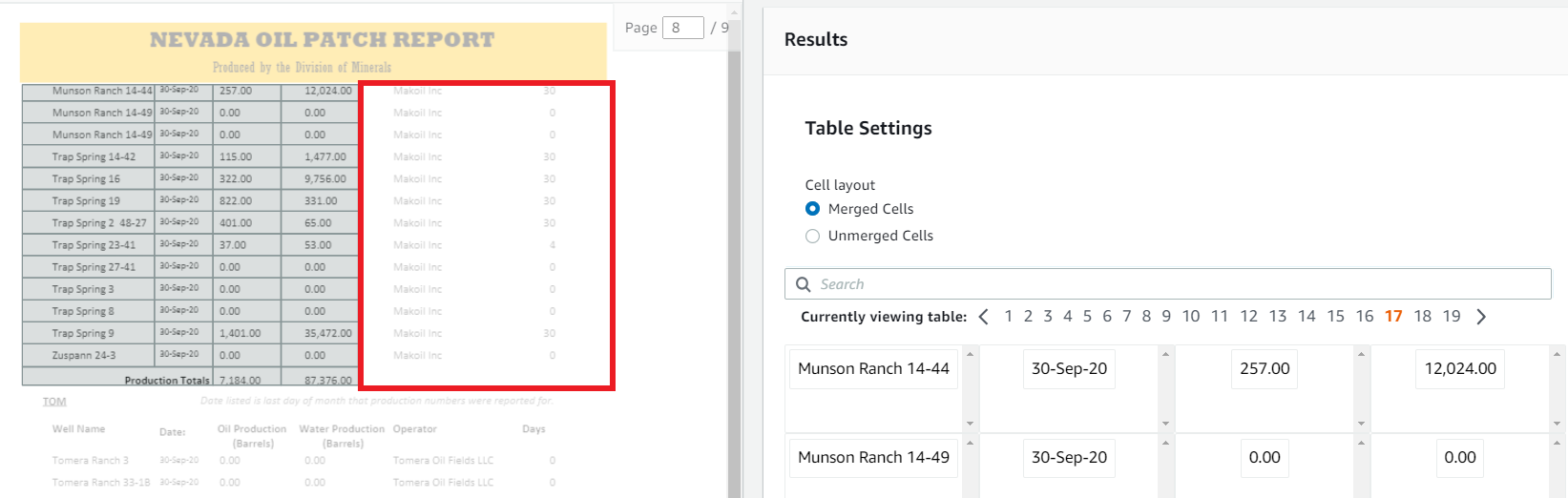
They're all considerable options. But are they enough for your need? It is hard to find a solution that guarantees 100% success rates. In some solutions, tables get extracted but form information is lost.
Even if all data is extracted, the structure and context of the information are lost.
On top of that, you will not find enterprise-level features like integrated security, user roles, and access, data management & sharing, 24x7 support, etc.
However, if you look for software that manages your business like CRM, payroll management, employee self-service, ticketing systems, etc., they come with all these features.
So why is such a software not readily available in the market?
Let's understand the major requirements of such a software:
Let's understand the major requirements of such a software:
- Nearly 100% data extraction success rates
- Preserve the key-value relationships in a form type information
- Dedicated support for failed cases
- Faster updates to the software to add support for all failed cases
- Enterprise-grade security
- Integrate enterprise single-sign-on mechanism
- User groups and roles
- Data sharing between groups
- Integration of extracted data with downstream processes within the enterprise
The list is so long and requirements are so specific to each organization that it becomes almost impossible to find off-the-shelf software in the market. You will have to hire someone to custom-build it.
This is where a need for an end-to-end PDF document extraction, processing, and comprehension solution, like CCTech offers, comes in.
Our USP is that we use multiple PDF extraction solutions and our own domain logic to enhance those results for the client.
We have developed online PDF extraction platforms for two Oil and Gas majors. Today our solutions are used by multiple teams within their organisation to instantly and easily extract large amount of pdf files.
Since PDF is a global format, avoiding a new and unique pattern is impossible. But the more we encounter them, the better our service gets because it constantly keeps adapting. If you've got a tough nut to crack in the form of a complex PDF, send it our way!
Comments
Recent posts